One diffusion model of the joint distribution P(X, Y), steered at test time — turning rigid input→output prediction into flexible, training-free output optimization.
∗Equal contribution · ✉Corresponding author · Fellow, IEEE
1CVLab, EPFL ·
2Fudan University ·
3Beihang University ·
4ELLIS Institute Finland & Aalto University
5The Hong Kong Polytechnic University
Summary
GenMed replaces task-specific medical predictors with a generative model of paired variables P(X, Y). At inference time, the observed input acts as a constraint that steers sampling toward a consistent pair, so the same model can handle standard segmentation, cross-modality transfer, degraded inputs, few-shot settings, and 3D shape completion.
Train once on paired data, then condition through test-time guidance.
02Use one-plane, tri-plane, multi-plane, or broken observations without retraining.
03Handle modality shift, few-shot training, and degraded scans.
04Turn the learned medical shape prior into an interactive completion engine.
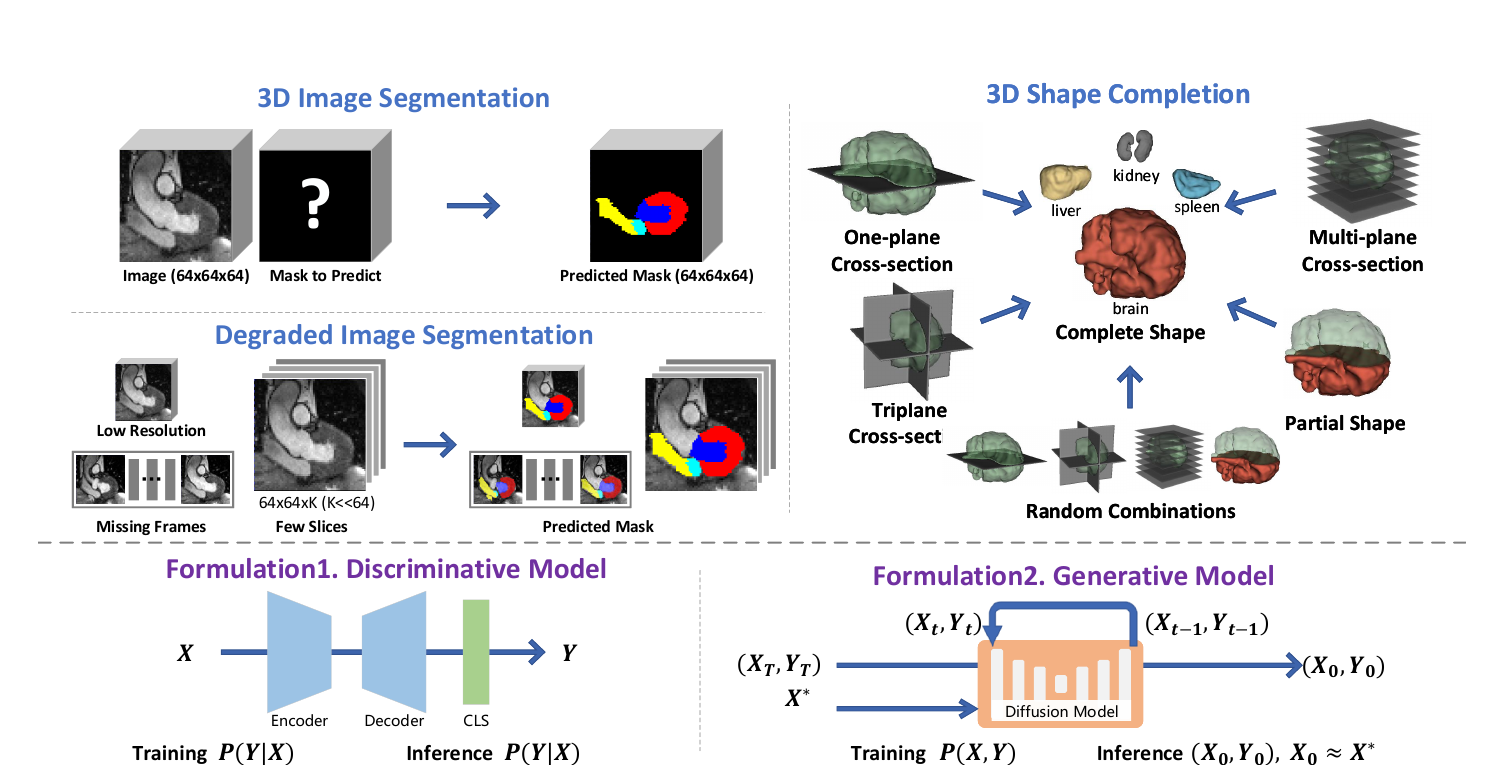
Data-driven medical AI is traditionally framed as a discriminative mapping from an input X to an output Y via a learned function f — a formulation that generalizes poorly across the heterogeneous data and modalities of real clinical settings. We propose a fundamentally different, generative paradigm: we model the joint distribution P(X, Y) with a diffusion model and reframe inference as a test-time output optimization problem.
By guiding the generative process to match observed inputs, GenMed enables flexible, gradient-based conditioning at inference time — without architectural changes or retraining — and naturally supports arbitrary, previously unseen combinations of observations. Extensive experiments demonstrate strong performance on standard and cross-modality segmentation, few-shot segmentation with only 2 or 4 training samples, degraded-input segmentation, shape completion from sparse and partial observations, and zero-shot transfer to a new domain.
To support these evaluations, we curated and released a large-scale text–shape dataset derived from MedShapeNet. Our results highlight the versatility of generative joint modeling as a foundation for reusable, task-agnostic medical AI systems.
Method
GenMed trains an unconditional diffusion model over data pairs (X, Y). At inference, a known observation X∗ guides sampling toward a consistent pair (X′, Y′) with X′ ≈ X∗ — so the model is trained once and conditioned on any signal afterwards.
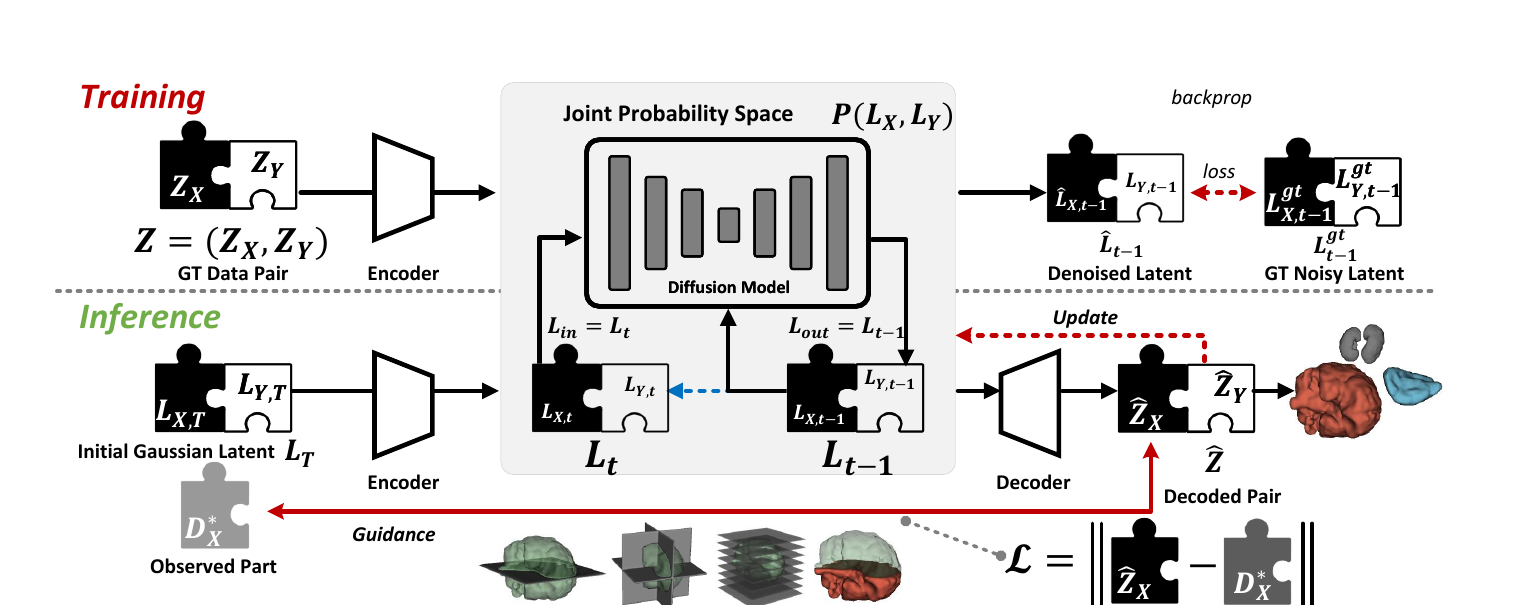
Modeling the joint distribution removes the need for a dedicated input-conditioning encoder, so a single model serves many tasks and any combination of observations.
A soft loss steers both paired variables together (GenMed-Full), avoiding the semantic gap of naive guidance and adapting to new inputs purely at test time.
Works directly on voxels for segmentation, and on encoded latents for 3D shapes — deferring decoding to the end of the denoising trajectory for stable shape completion.
The same pairwise paradigm supports an end-to-end diagnostic pipeline: segment the raw scan, then complete the shape with the pretrained prior to recover geometrically plausible anatomy under corrupted imaging.
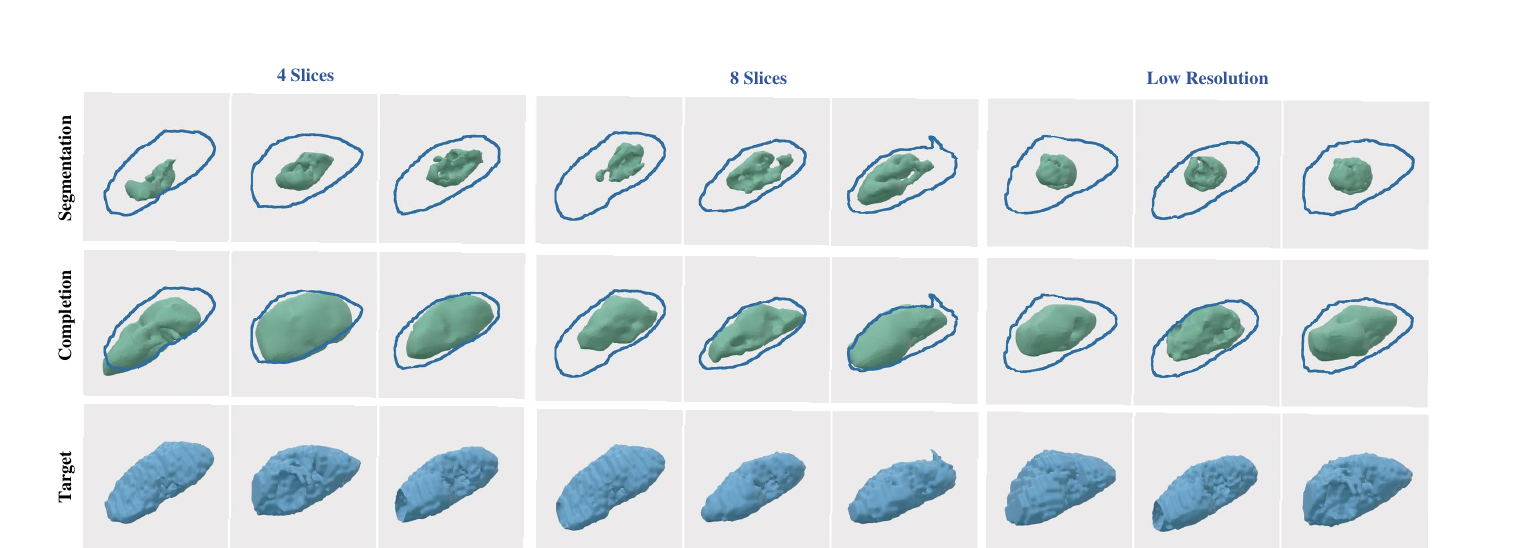
Mask-Prompt Guidance
GenMed treats a visual prompt as a constraint on the generated pair rather than as a fixed input channel. This lets the same pretrained prior respond to sparse slices, intersecting planes, missing regions, and noisy partial evidence.
A single cross-section anchors the anatomy while the prior fills the unobserved volume.
Three orthogonal slices provide stronger spatial constraints without changing the model.
Multiple sparse sections guide denser completion while still leaving shape inference to the prior.
Missing or corrupted regions are treated as partial observations to be reconciled during sampling.

Results · Segmentation
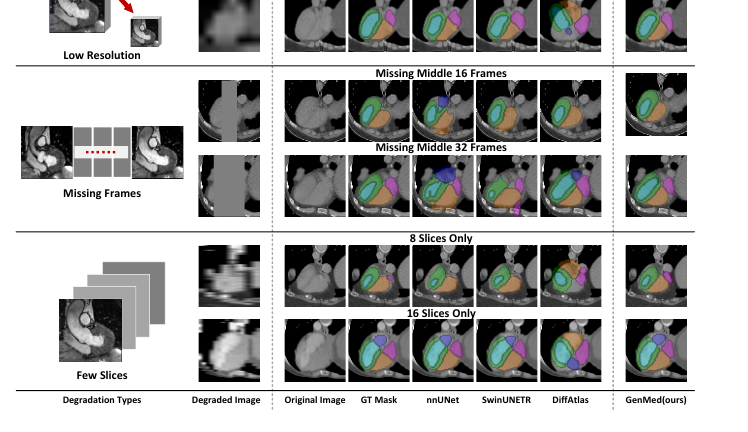
A model trained on full 3D volumes transfers — with no retraining — to a different modality, to as few as 2–4 training samples, and to severely degraded inputs (low resolution or missing slices).
| Method | Standard (TS) | CT → CT | Zero-shot CT→MRI | 2-shot CT |
|---|---|---|---|---|
| nnU-Net | 83.7 | 62.0 | 35.3 | 47.0 |
| SwinUNETR | 81.4 | 59.8 | 32.3 | — |
| Input-Cond. Diffusion | 81.7 | 55.0 | 31.9 | 41.2 |
| GenMed-Full (Ours) | 85.4 | 83.8 | 59.9 | 77.7 |
Datasets: TotalSegmentator (TS) and MM-WHS. The gap widens dramatically under distribution shift — cross-modality and few-shot — where conditional models lose most of their accuracy.
Results · Shape Completion
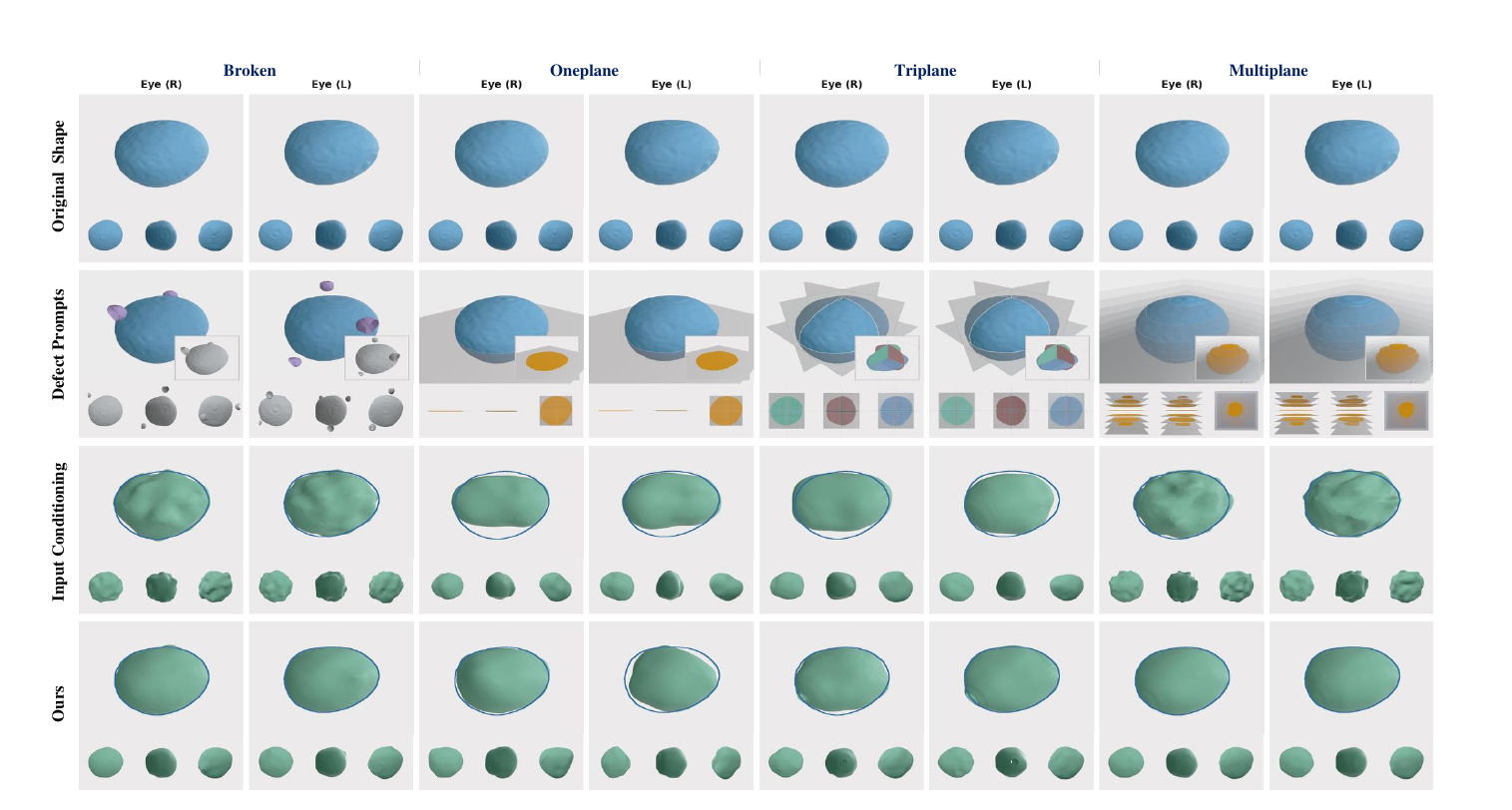
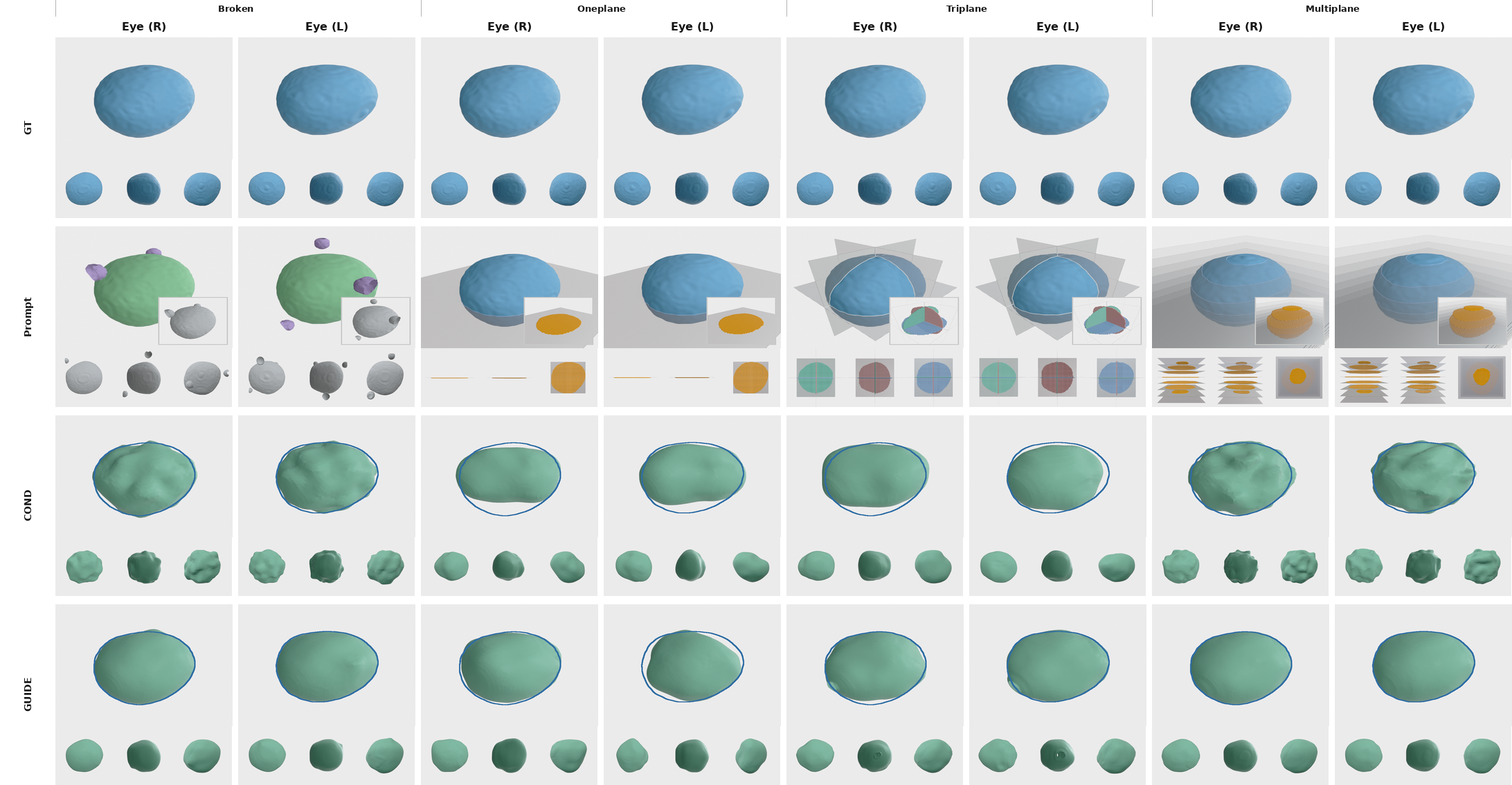
A single model trained only on complete shapes completes anatomy from diverse, previously unseen observations — single-, multi-, and tri-plane cross-sections, broken regions, and stochastically sampled corruptions.

| Method | MMD ↓ | COV ↑ | 1-NNA ↓ |
|---|---|---|---|
| SDFusion | 2.07 | 52.33 | 70.44 |
| Diffusion-SDF | 3.19 | 41.05 | 83.49 |
| OctFusion | 8.75 | 24.14 | 87.56 |
| GenMed-Base (Ours) | 1.16 | 52.80 | 66.24 |
A medical-tailored SDF backbone yields higher-fidelity shapes and a generated distribution closer to the real one.
Beyond generation, GenMed turns the same prior into a completion engine. On the hardest multi-plane prompts it reaches 75.9 Dice and the lowest worst-case error (UHD 10.2), surpassing input-conditioning baselines.
A notable finding: for these dense, voxel-level geometric prompts, classifier-free guidance variants underperform direct conditioning — yet GenMed's pairwise formulation adapts naturally, recovering finer boundary detail even when only a single slice is available.
Interactive
Rotate any mesh — all columns stay camera-synced. The updated cases include smoothed broken-organ prompts for pancreas, pulmonary artery, and adrenal gland, alongside gallbladder, eyeball, and kidney examples. We compare the ground-truth shape, the input conditioning baseline, and GenMed (Ours), reporting Dice ↑, CD ↓ and UHD ↓ vs. ground truth on each method. Plane prompts render the observed cutting planes through a faint full-shape ghost.
Drag to rotate · scroll to zoom · plane prompts show the observed cutting planes through a faint ghost of the full shape; broken prompts show the observed, redundant and unobserved regions. CD/UHD use the paper's metric (×100), Dice on the SDF occupancy.
Gallery
Slide through qualitative results — use the arrows, the dots, swipe, or your keyboard ←/→. Click any panel to enlarge.


Citation
@article{zhang2026genmed, title = {GenMed: A Pairwise Generative Reformulation of Medical Diagnostic Tasks}, author = {Zhang, Hantao and Guo, Weidong and Liu, Yuhe and Yang, Jiancheng and Bhagavan, Sathvik and Xu, Mingda and Shi, Danli and Fua, Pascal}, journal = {arXiv preprint arXiv:2605.10645}, year = {2026} }